Ces dernières années les microservices sont devenus de plus en plus populaires. Pourquoi ? Devriez-vous les utiliser ? Comment les mettre en place ? Autant de questions auxquelles cet article de Victor Farcic apporte un début de réponse pour vous aider dans vos choix d’architecture logicielle.
Introduction
Au début les applications étaient petites et simples et ne comportaient que peu d’exigences. Avec le temps, les exigences et les besoins ont grandi et nos applications avec elles pour devenir plus grosses et plus complexes. Cela s’est traduit par des serveurs monolithiques développés et déployés d’une seul traite. Les Microservices sont, en un sens, un retour aux sources avec des applications simples qui remplissent les besoins de complexité d’aujourd’hui en fonctionnant ensemble à travers l’utilisation des APIs de chacune des autres.
C’est quoi un serveur monolithique ?

La meilleure façon d’expliquer ce que sont les microservices; c’est encore de les comparer avec l’inverse : les serveurs monolithiques. Ils sont développés et déployés de manière unitaire. Dans le cas de Java, le résultat est souvent un fichier WAR ou JAR. C’est aussi vrai pour C++, .Net, Scala et beaucoup d’autres langages de programmation.
Une grande partie de l’histoire du développement logiciel est marqué pour l’augmentation continue de la taille des applications que nous développons. Au fur et à mesure que nous ajoutons de plus en plus de choses dans nos applications nous augmentons leur complexité et leur taille et cela ralentit le développement, et la vitesse à laquelle nous pouvons tester et déployer.
Avec le temps nous avons commencé à diviser nos applications en couches : la couche de présentation, la couche métier, la couche d’accès aux données, etc. Cette séparation est plus logique que physique. Même si le développement est devenu un peu plus simple, nous avons toujours besoin de tout tester et de tout déployer à chaque changement ou à chaque version. Il n’est pas rare dans certains environnements professionnels d’avoir des applications qui prennent des heures à compiler et à déployer. Tester, en particulier les régressions, peut virer au cauchemar et prendre et certains cas des mois. Avec le temps, notre capacité à faire des changements qui n’affectent qu’un seul module est réduite. Le principal objectif des couches est de faire en sorte qu’elles puissent être aisément remplacées ou mises à jour. Cette promesse n’a jamais vraiment été tenue. Remplacer quelque chose dans de grosses applications monolithiques c’est jamais vraiment facile et sans risques.
Dimensionner de tels serveurs signifie dimensionner l’application entière et obtenir une utilisation très inégale des ressources. Si nous avons besoin de plus de ressources, nous sommes forcés de tout dupliquer sur un nouveau serveur, même si le goulot d’étranglement ne concerne qu’un seul module.
Que sont les microservices ?
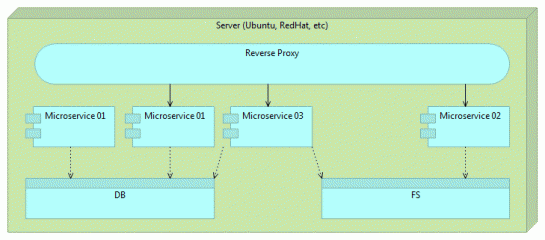
Les microservices sont une approche d’architecture et de développement d’une seule application composées de petits services. Ce qu’il faut bien comprendre dans les microservices, c’est leur indépendance. Chacun est développé, testé et déployé séparément des autres. Chaque service tourne dans un processus séparé. La seule relation entre les différents microservices est l’échange de données effectué à travers les différentes APIs qu’ils exposent. Ils reprennent, en un sens, l’idée de petits programmes et de tuyaux utilisés dans Unix/Linux. La majorité des programmes Linux sont petits et génèrent une sortie. Cette sortie peut-être utilisée comme entrée par d’autres programmes. Lorsqu’on les enchaîne, ces programmes peuvent réaliser des opérations très complexes. C’est une complexité né de la combinaison de quelques petites unités simples.
Les aspects clef des microservices sont :
- Ils ne font qu’une seule chose et sont responsables d’une fonctionnalité,
- chaque microservices peut être conçu à l’aide de n’importe quel outil ou langage puis que chaque microservice est indépendant des autres,
- Ils sont vraiment faiblement couplés puisque chaque microservice est physiquement séparé des autres,
- Indépendance relative entre les différentes équipes qui développement les différents microservices (en partant du principe que les APIs qu’ils exposent sont définis à l’avance).
- Facilité des tests et du [déploiement ou de la livraison continue](http://technologyconversations.com/2014/11/27/continuous-deployment-introduction/).
Un des problèmes avec les microservices est de décider quand les utiliser. Au début, lorsque l’application est encore petite, les problèmes que tentent de résoudre les microservices n’existent pas encore. Toutefois, une fois que l’application a grossi et qu’on peut préconiser des microservices, le coût de migration vers une architecture différente peut s’avérer trop important. Les équipes expérimentées peuvent décider d’utiliser des microservices dès le départ en sachant que la dette technique qu’ils auraient à payer plus tard serait plus coûteuse que de commencer à travailler dès le début avec des microservices.
Souvent, comme c’est le cas pour Netflix, eBay et Amazon, les applications monolithiques commencent à évoluer vers des microservices de façon graduelle. De nouveaux modules sont développés en tant que microservices et intégrés au reste du système. Une fois leur valeur prouvée, des parties de l’application monolithique existante sont refactorisées en microservices.
Une des chose que critique les plus les développeurs d’applications professionnelles est la décentralisation du stockage de données.
Alors que les microservices peuvent fonctionner (avec quelques ajustements) en stockant les données de manière centralisée, la possibilité de décentraliser également cette partie devrait, à minima, être étudiée.
Le choix de stocker séparément (de façon décentralisée) les données relatives à un service et d’emballer tout ça dans le même conteneur pourra souvent se révéler être une meilleure option que de stocker les données dans une base de données centralisée. Nous ne proposons pas d’utiliser systématiquement le stockage décentralisé mais de prendre cette option en considérant pendant la conception de microservices.
Inconvénients
Accroissement de la complexité opérationnelle et du déploiement
Un des principaux arguments contre les microservices est qu’il accroit la complexité opérationnelle et celle du déploiement. Cet argument est vrai mais grâce à à des outils relativement nouveaux, il peut être nuancé. Les outils de gestion de configuration (CM) peuvent gérer des configurations d’environnement et de déploiement relativement facilement. L’utilisation de conteneurs avec Docker réduit grandement les difficultés de déploiement que peuvent causer les microservices.
Les outils de GC et Docker nous permettent de déployer et de dimensionner facilement. Un exemple est présent dans l’article Continuous Deployment: Implementation with Ansible and Docker.
À mon avis, l’argument de l’accroissement constant de la complexité du déploiement ne prend généralement pas en compte les avancées que nous avons pu voir depuis quelques années dans le domaine et est donc grandement exagéré. Cela ne veut pas dire qu’une partie du travail n’a pas été transférée du développement vers DevOps. C’est définitivement le cas. Néanmoins, les bénéfices sont dans de nombreux cas bien plus importants que les inconvénients que produisent ce changement.
Les appels de processus distants
Un autre contre-argument est la baisse de la performance causée par les appels de processus distants. Les appels internes des classes et des méthodes sont plus rapides et ce problème ne peut être omis. La manière dont la perte de performance va impacter un système est à analyser au cas par cas. Un facteur important est la façon dont nous allons segmenter notre système. Si nous adoptons une approche extrême avec de tous petits microservices (certains proposent qu’ils fassent entre 10 et 100 lignes de code) cet impact pourrait être considérable. J’aime créer des microservices organisés autour des fonctionnalités comme les utilisateurs, le panier d’achat, les produits, etc.
Cela réduit le nombre d’appel à des processus distants. Il est également important de noter que si les appels d’un microservices à un autre se sont à travers un LAN interne rapide, l’impact négatif est relativement faible.
Avantages
Les avantages qui suivent ne représentent qu’une partie de ce que les microservices peuvent apporter. Cela ne veut pas dire que le même avantage n’existe pas dans d’autres types d’architecture mais avec les microservices ils peuvent être un poil plus visibles qu’avec d’autres options.
Dimensionnement
Dimensionner les microservices est plus facile qu’avec des applications monolithiques. Alors que dans le deuxième cas nous dupliquons toute l’application sur une nouvelle machine, avec les microservices nous ne dupliquons que ce qui a besoin d’être redimensionné. Non seulement nous ne pouvons dimensionner que ce qui a besoin de l’être mais nous pouvons mieux distribuer les choses. Nous pouvons par exemple, mettre un service qui fait une utilisation intensive du CPU avec un autre qui consomme beaucoup de RAM pendant que nous déplaçons un deuxième service gourmand en CPU sur un matériel différent.
Innovation
Les serveurs monolithiques, une fois l’architecture initiale mise en place, ne laisse pas trop de place à l’innovation. De par leur nature, changer les choses prend du temps et l’expérimentation est très risquée puisque cela peut potentiellement affecter l’ensemble. On ne peut pas par exemple changer Apache Tomcat pour NodeJS simplement parce que ce serait plus adapté pour un module en particulier.
Je ne suggère pas que nous devrions changer de langage de programmation, de serveur, de persistance, etc. pour chaque module. Mais, les serveurs monolithiques tendent à l’opposé et les changements sont risqués voire malvenus. Avec les microservices, nous pouvons choisir séparément ce que nous pensons être la meilleure solution pour chaque service. Un pourrait utiliser Apache Tomcat alors que l’autre utiliserait NodeJS. Un pourrait être écrit en Java et l’autre en Scala. Je ne suis pas en train de défendre le fait que chaque service devrait être différent du reste des autres mais chacun peut être conçu de la manière dont nous pensons qu’elle répond le mieux à l’objectif fixé.
De plus, les modifications et les expériences sont plus faciles à faire. Après tout, quoi que l’on fasse, cela n’affecte qu’un des nombreux microservices et pas le système dans son ensemble du moment que l’API est respectée.
La taille
Puisque les microservices sont petits, ils sont plus faciles à comprendre. Il y a beaucoup moins de code à parcourir pour comprendre ce qu’un micro service fait. Cela simplifie grandement en soi le développement, particulièrement lorsqu’un nouveau rejoint le projet. En plus de cela, tout le reste a tendance à être plus rapide. Les IDE fonctionnent plus vite avec un petit projet, comparé à ceux utilisés pour les applications monolithiques. Ils démarrent plus vite, puisque il n’y a pas d’énormes serveurs ou un grand nombre de bibliothèques à charger.
Déploiement, marche arrière et isolation d’une erreur
Le déploiement est plus rapide et plus simple. Déployer quelque chose de simple est plus rapide (voire plus facile) que déployer quelque chose de gros. Dans le cas où nous réalisons qu’il y a un problème, ce problème a potentiellement un impact limité et peut être annulé bien plus facilement.
Avant que nous ne fassions marche arrière, l’erreur est isolée dans une petite partie du système. La livraison ou déploiement continu peut être fait à une vitesse et une fréquence qui ne serait pas possible avec de gros serveurs.
Pas besoin d’engagement sur le long terme
Un des problèmes fréquents avec les applications monolithiques est l’engagement. Nous sommes souvent obligés de choisir dès le début l’architecture et les technologies qui devront durer un long moment. Après tout, nous construisons quelque chose de gros qui devra durer longtemps. Avec les microservices, cet besoin d’un engagement sur le long terme n’est pas si important. Changez de langage de programmation dans un microservice et s’il s’avère que c’est un bon choix, appliquez le à d’êtres. Si l’expérience échoue ou n’est pas optimale, il n’y a qu’une toute petite partie du système qui a besoin d’être refaite. C’est aussi valable pour les frameworks, les bibliothèques, les serveurs, etc. Nous pouvons même utiliser différentes base de données. Si une pincée de NoSQL semble être le meilleur choix pour un microservice en particulier, pourquoi ne pas l’utiliser et l’intégrer à l’intérieur du conteneur ?
Bonnes pratiques
La plupart des bonnes pratiques suivantes peuvent être généralement appliquées aux architectures orientées service. Maintenant, avec les microservices, elles deviennent encore plus importantes et bénéfiques.
Conteneurs
Gérer beaucoup de microservices peut facilement devenir une tâche très complexe. Chacun peut être écrit dans un langage de programmation différent, peut demander un type différent de serveur (léger si possible) ou peut avoir recours à différents jeux de bibliothèques. Si chacun de ces services est livré sous forme de conteneur, alors la plupart de ces problèmes disparaîtront. Tout ce que nous avons à faire est de lancer le conteneur avec par exemple Docker et espérer que tout ce dont nous avons besoin est dedans.
Microservices proxy ou Passerelle d’API
Les interfaces client de grandes entreprises peuvent avoir besoin d’appeler des dizaines voire des centaines de requêtes HTTP (comme c’est le cas pour Amazon.com). Souvent les requêtes mettent plus de temps à être appelées qu’à recevoir la réponse.
Les microservices proxy peuvent aider dans ce genre de cas.
Leur objectif est d’appeler différents microservices et de retourner un service agrégé. Ils ne devraient contenir aucune logique mais simplement regrouper ensemble plusieurs réponses et répondre avec des données agrégées à l’utilisateur.
Reverse proxy
N’exposez jamais directement l’API d’un microservice. S’il n’y a pas un quelconque type d’orchestration, la dépendance entre l’utilisateur et le microservice peut devenir si importante qu’elle peut nous priver de la liberté que les microservices sont censés nous donner. Des serveurs légers comme Apache Tomcat ou nginx sont très bons dans l’exécution de tâches de reverse proxy et peuvent aisément être utilisés avec peu d’effort supplémentaire. Merci de consulter l’article Continuous Deployment: Implementation pour voir une implémentation possible d’utiliser un reverse proxy avec Docker and quelques autres outils.
Approche minimaliste
Les microservices ne devraient contenir que des paquets, des bibliothèques et des frameworks dont ils ont vraiment besoin. Plus ils sont petits, mieux c’est. C’est tout l’inverse de l’approche adoptée par les applications monolithiques. Alors qu’auparavant nous aurions eu recours à des serveurs JEE comme JBoss qui regroupent tous les outils sont nous aurions pu avoir besoin ou pas, les microservices fonctionnent mieux avec des solutions beaucoup plus minimalistes. Avoir des centaines de microservices qui embarquent tous un serveur JBoss est totalement disproportionné. Apache Tomcat, par exemple, est une bien meilleure option. J’ai tendance à choisir des solutions encore plus petites comme par exemple Spray, un serveur pour API Restful très léger. Ne prenez que ce dont vous avez besoin.
La même approche devrait aussi être utilisée au niveau du système d’exploitation. Si nous devons déployer des microservices sous forme de conteneurs Docker, CoreOS pourra être une meilleure solution que par exemple Red Hat ou Ubuntu.
Déjà débarrassé des choses dont nous n’avons pas besoin, il nous permet de mieux exploiter les ressources.
La gestion de la configuration est un must
Plus le nombre de microservices augmente, plus nous avons besoin de gestion de configuration (CM). Déployer plusieurs microservices sans des outils comme Puppet, Chef ou Ansible (pour n’en citer que quelques uns) vire très vite au cauchemar. En fait, mis à part pour des solutions extrêmement simples, ne pas utiliser d’outils de gestion de configuration est une perte de temps, qu’il y ait des microservices ou non.
Des équipes transversales fonctionnelles
Bien qu’il n’y ait pas de règles qui dictent la manière dont les équipes doivent être structurées, les microservices sont mieux conçus lorsque l’équipe qui travaille sur un est pluri-disciplinaires. Une seule équipe devrait en être responsable du début (conception) à la fin (déploiement et maintenance). Les microservices sont trop petits pour être gérer d’une équipe à l’autre (équipes d’architecture/conception, de développement, de tests, de déploiement et de maintenance). Il est préférable d’avoir une seule équipe entièrement responsable du cycle de vie d’un microservice. Dans certains cas une équipe pourra être responsable de plusieurs microservices, mais la responsabilité d’un microservice ne devrait pas être répartie entre plusieurs équipes.
Versionnement d’API
Toute API devrait être versionnée et c’est aussi vrai pour les microservices. Si certaines changements cassent le format de l’API, cette modification devrait être livrée dans une version à part. Dans le cas des APIs publiques ou des microservices, nous ne savons pas avec certitude qui les utilise et donc devons assurer une retro-compatibilité ou à défaut donner le temps aux utilisateurs de pouvoir s’adapter. Il y a une partie sur la gestion des versions d’API publier dans l’article API REST avec JSON.
En résumé
Les microservices ne sont pas la réponse à tous nos problèmes. Rien ne l’est. Ils ne sont pas la façon dont toutes les applications devraient être créées. Il n’y a aucune solution qui adresse tous les cas de figures.
Les microservices existent depuis longtemps et ont connu un regain de popularité depuis quelques années. Il y a plusieurs facteurs responsables de cette tendance, le dimensionnement étant probablement le plus important d’entre eux.
L’émergence de nouveaux outils et en particulier de Docker nous permettent de voir les microservices sous un nouveau jour et suppriment une partie des problèmes que leur développement et leur déploiement avaient crées.
L’utilisation des microservices par les « grands » comme Amazon, Netflix, eBay et d’autres, donne assez de confiance pour que ce style d’architecture soit prêt à être évalué (si ce n’est utilisé) par les développeurs d’applications professionnelles.
Pour plus d’informations sur les microservices, vous pouvez lire : Microservices Development with Scala, Spray, MongoDB, Docker and Ansible
Crédit photo: zamito44 via photopin CC
Super article, sa m’a donné envie de donné une chance a docker